This article was automatically translated from the original Turkish version.
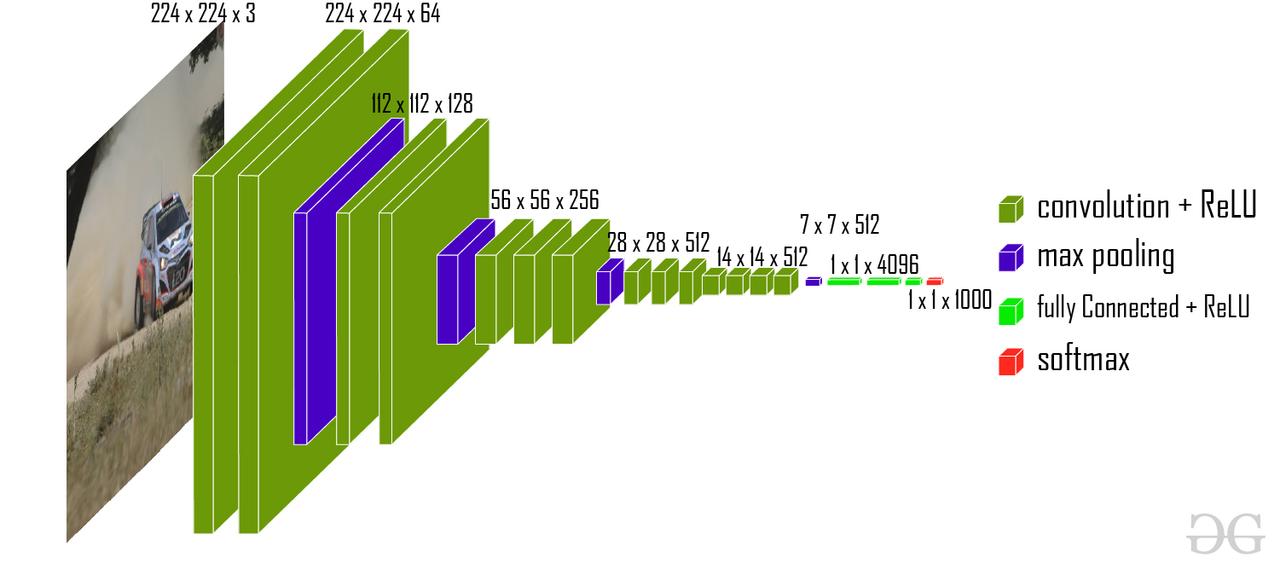
VGG16 is a deep convolutional neural network (CNN) architecture developed for visual recognition tasks. Proposed in 2014 by the Oxford University Visual Geometry Group (VGG), this model achieved high success in the ImageNet competition that same year and became a pivotal milestone in the evolution of deep learning based image processing models. The term “16” refers to the number of layers in the model (13 convolutional + 3 fully connected).
The fundamental design philosophy of VGG16 is to increase depth by using a large number of small filters (3×3 convolutions), enabling the learning of more complex patterns. This approach demonstrated that using successive small filters outperforms larger filters in terms of model performance.

VGG 16 Architecture (
VGG16’s architecture enables more detailed feature learning by increasing depth through small filters.
VGG16 consists of a total of 16 weighted layers:
VGG16 has been used as a foundational component in various image-based tasks:
GeeksforGeeks. "VGG-16 CNN Model." GeeksforGeeks. Accessed April 20, 2025. https://www.geeksforgeeks.org/vgg-16-cnn-model/.
Khaliki, Mohammed Zafer, and Muhammet Sinan Başarslan. “Brain Tumor Detection from Images and Comparison with Transfer Learning Methods and 3-Layer CNN.” *Scientific Reports* 14 (2024): 2664. Accessed April 20, 2025. https://doi.org/10.1038/s41598-024-52823-9.
Simonyan, Karen, and Andrew Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” *arXiv preprint* arXiv:1409.1556 (2014). Accessed April 20, 2025. https://arxiv.org/abs/1409.1556.
VGG16 Architecture
Layer Structure
Features and Advantages
Disadvantages
Applications